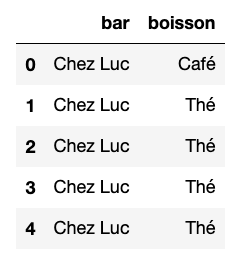
Une des problématiques récurrentes pour les web analystes est d’avoir à travailler avec de la donnée pauvre et/ou de mauvaise qualité. Dans certains cas, y compris avec de la donnée Google Analytics, il est possible de rectifier le tir. Plus particulièrement quand Google Analytics est déployé dans sa version Premium, désormais baptisée Google Analytics 360.
Nous allons voir ici comment grâce à deux fonctionnalités particulièrement utiles de GA360 et grâce à un petit peu de processing, il est possible d’enrichir facilement et rapidement sa donnée web. Ceci pourra être utile principalement dans les cas suivants :
-
- Palier une lacune dans le marquage actuel du site : vous souhaitez par exemple créer une custom dimension « Auteur » et la valoriser via l’import de données
- Réaliser une analyse ponctuelle : déployer au sein d’une custom dimension le résultat d’un algorithme de scoring basé sur une ou plusieurs dimensions / statistiques
- Commencer ses analyses avant la mise en place d’un nouveau marquage: analyser des données existantes en valorisant une custom dimension ou une custom metric avant même son déploiement au sein du marquage.
- Valoriser de manière rétroactive une dimension récemment intégrée au plan de marquage : une nouvelle dimension a été créée. Celle-ci est correctement alimentée par le nouveau marquage, mais vous souhaitez la valoriser de manière rétroactive
Cas client : classer toutes les URL d’un site par thématique
Je vous propose ici un tutoriel basé sur un cas client concret. La problématique est simple : on souhaite attribuer une thématique à chaque URL d’un site. Pour cela, on va se baser sur les termes contenus dans chaque URL. Cette classification se traduira par la création et la valorisation d’une nouvelle custom dimension au sein de Google Analytics.
Dans un monde parfait, ce type d’implémentation est réalisé en amont de la définition des KPI, des objectifs et des analyses. Mais ici, il n’était pas possible de toucher au plan de marquage et in-fine à l’implémentation. Nous allons donc voir comment enrichir de manière rétroactive environ 700 000 URL en quelques clics et en dix secondes de traitement.
Une fois la nouvelle custom dimension valorisée, il sera possible de l’utiliser au sein de tous les rapports natifs, des custom reports et des requêtes API. On pourra donc la croiser avec l’ensemble des statistiques et dimensions disponibles au sein de l’environnement GA.
J’ai découpé ce tutoriel en trois étapes clefs :
- Exporter de la donnée non échantillonnée via un « Unsampled Report». Le but étant de récupérer un CSV contenant un maximum d’URL sur une période donnée. Cette liste d’URL servira de clef de jointure pour notre nouvelle dimension.
- Enrichir et nettoyer la donnée en local grâce à Python. L’objectif est de créer une nouvelle colonne au sein de notre CSV dont la valeur de chaque ligne dépendra de l’URL, en fonction des règles qu’on aura établies.
- Réimporter la donnée au sein de GA via le Dimension Widening. Une fois notre CSV construit, il faut importer ce dernier au sein de GA pour rendre notre dimension exploitable. Une option spécifique à GA360 sur l’import de données, appelée « Query Time », nous sera particulièrement utile.
J’ai détaillé au maximum les trois parties, mais n’hésitez pas à faire un focus ou à balayer rapidement celles qui vous intéressent particulièrement ou celles que vous maîtrisez déjà.
Etape #1 : Exporter la donnée – L’Unsampled Report à la rescousse
Objectif : récupérer un CSV avec une colonne « Pages » exhaustive.
Un des avantages de Google Analytics 360 est de pouvoir exporter de la donnée non échantillonnée via les « Unsampled Reports ». Au sein d’un site à fort volume d’audience couplé à un nombre de pages indexées élevé, on peut rapidement devoir analyser plusieurs centaines de milliers de pages, rattachées à plusieurs millions de sessions différentes.
L’unsampled report présente deux avantages :
- Récupérer de la donnée non échantillonnée, même si le rapport dépasse la limite théorique des 100 millions de sessions. Rappelons que cette limite est de 500 000 sessions sur Google Analytics Standard. Au-delà de ces limites, un sampling est automatiquement appliqué.
- Récupérer un nombre de lignes allant jusqu’à 3 millions, contre seulement 5000 pour les custom reports standards. Et c’est cette fonctionnalité qui est à mes yeux de loin la plus puissante. Dans une majorité de cas, on pourra donc récupérer de manière exhaustive toutes les valeurs de n’importe quelle dimension. Attention en revanche au croisement de dimensions qui pourra très rapidement augmenter le nombre de lignes et exploser le quota des 3 millions.
Création du rapport personnalisé
Pour créer un Unsampled Report, il faut commencer par créer un custom report standard.
On va créer un custom report avec une seule dimension « Pages ». On rajoute la statistique « Pages vues » puisqu’un rapport doit contenir à minima une dimension et une statistique. Vous pouvez rajouter d’autres statistiques pour anticiper vos besoins, mais ici elles ne nous seront pas utiles. En revanche, ne rajoutez aucune autre dimension, pour ne pas démultiplier les valeurs de la colonne « Pages ».
Une fois le rapport créé, choisissez un date range suffisamment large pour viser l’exhaustivité sur la colonne « Pages ».
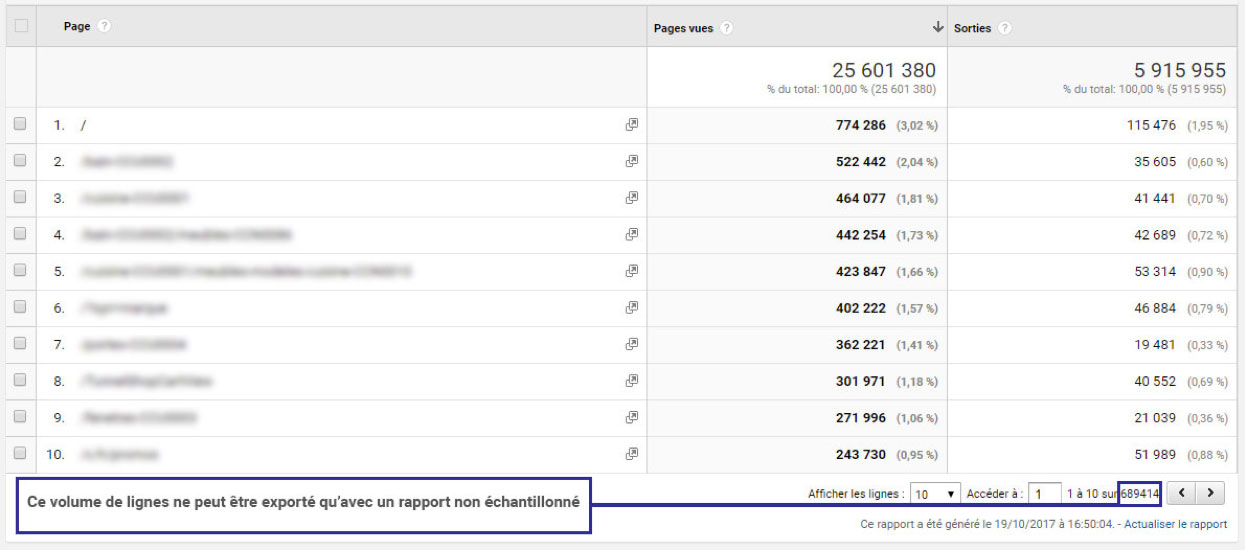
Une fois votre rapport prêt, cliquez sur « Exporter » puis « Rapport non échantillonné ».
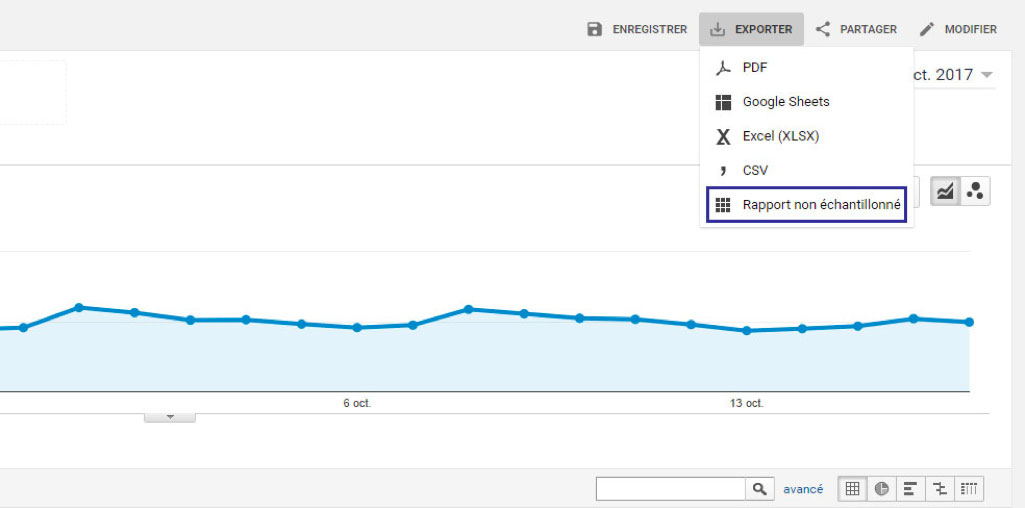
Vous recevrez un email vous avertissant que le rapport non échantillonné est prêt. Vous pourrez également y accéder via l’onglet du menu dédié :
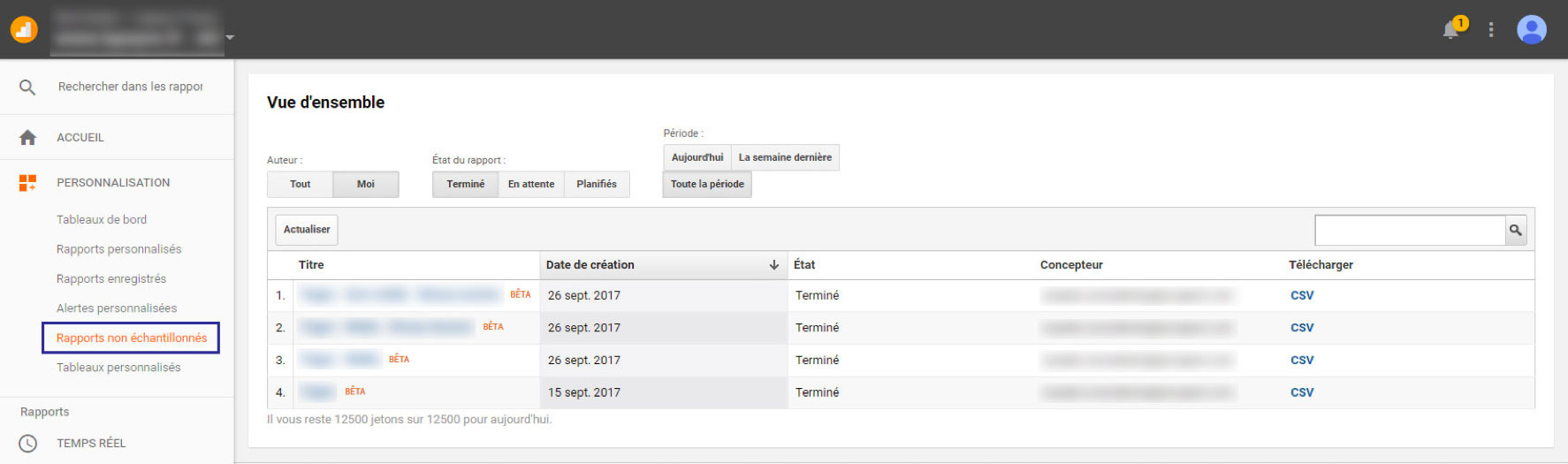
Ensuite, il suffit de télécharger le rapport au format CSV. De mon côté, j’ai exporté un rapport contenant « Page » en dimension, « Pages vues » et « Sorties » en statistiques, ce qui donne ça :
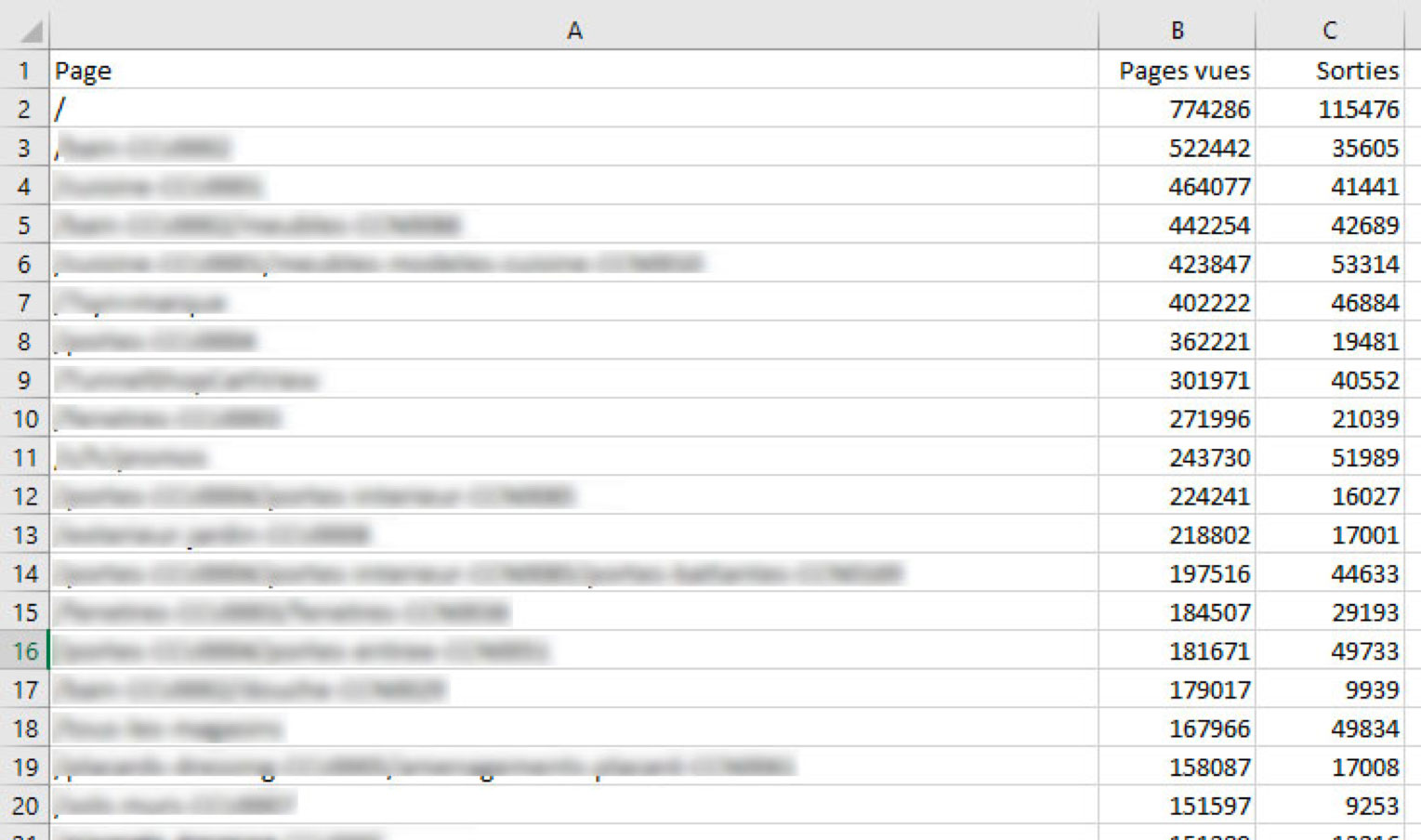
Pour plus d’informations sur l’extraction de donnée GA non échantillonnée, je vous renvoie vers deux excellents articles de LunaMetrics :
Etape #2 : Enrichir facilement la donnée grâce à Python et la librairie Pandas
Objectif : enrichir le CSV préalablement obtenu avec une nouvelle colonne. Cette colonne contiendra les valeurs qu’on souhaite importer au sein de notre dimension « Thématique ». La jointure se fera grâce à la colonne « Page ».
Prérequis :
- Avoir suivi l’étape 1 du tutoriel
- Avoir créé une nouvelle custom dimension « Thématique » au sein de GA 360
A ce stade, vous devriez avoir un CSV dont la première colonne est la dimension « Page », suivie des statistiques que vous avez décidé d’intégrer dans le rapport.

L’objet de l’article n’est pas d’expliquer comment installer un environnement Python. Notons simplement que j’ai réalisé l’ensemble des opérations au sein d’un Jupyter Notebook. Je vais en revanche détailler les différentes étapes du code, qu’on peut découper ainsi :
- Chargement des librairies (standards et externes)
- Création d’une fonction qui renvoie une thématique en fonction du contenu de l’URL
- Importation du CSV en tant que DataFrame
- Création d’une nouvelle colonne valorisée grâce à notre fonction précédemment créée
- Enregistrement du DataFrame en tant que CSV
Chargement des librairies
Nous allons avoir besoin de trois librairies, dont deux faisant partie de la librairie standard.
- « time » qui va nous permettre de mesurer le temps d’exécution de notre script.
- « re » pour réaliser des expressions régulières.
- « Pandas ». Développée par Wes McKinney, cette librairie a largement contribué au succès de Python en Data Science et a donné toutes les armes au langage pour rivaliser notamment avec R. Dans notre cas, elle va nous permettre d’importer notre CSV sous forme de « DataFrame ». Un DataFrame est un objet Pandas modélisant une matrice à deux dimensions. Les colonnes possèdent des labels, et chaque ligne est indexée.
1
2
3
4
5
| # Import des librairies
import pandas as pd
import re
import time |
# Import des librairies
import pandas as pd
import re
import time
Création de notre fonction d’attribution de thématique
C’est ici que tout se joue. Dans notre cas, notre fonction de classement va être très basique. On va simplement chercher des correspondances d’expression régulière au sein de la chaîne de caractères passée en argument. Rien n’empêche en revanche d’imaginer quelque chose de plus complexe, basé sur plusieurs critères.
Afin de préserver la confidentialité du client, j’ai simplifié la fonction, en réduisant notamment le nombre de vérifications. Mais le principal y est. L’idée est de récupérer une URL en paramètre. On teste ensuite plusieurs expressions régulières pour trouver celle qui correspond. Dès qu’une correspondance est trouvée, on renvoie la thématique associée. Si aucune condition n’est trouvée, alors on renvoie une valeur par défaut.
Si cette fonction avait une chance de se retrouver dans la nature, il faudrait la renforcer. En vérifiant notamment que l’argument passé est bel et bien une URL.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| # Fonction retournant une thématique en fonction du contenu de l'URL
def page_theme(url):
""" Assignation d'une thématique en fonction du contenu de l'URL """
theme = ""
if (re.search('^/
<h3>Importation du CSV et création de la nouvelle colonne « Thématique »</h3>
<pre lang="python" line="1"># On enregistre l'heure avant de démarrer le processing
startTime = time.time()
# On récupère le rapport non échantillonné
gadf = pd.read_csv('Pages.csv', encoding='utf-8')
# On garde uniquement la colonne "Pages" On peut également choisir la colonne à l'import
del gadf['Pages vues']
del gadf['Sorties']
# Création d'une colonne "Theme". Application de la fonction page_theme()
gadf['Theme'] = list(map(page_theme, gadf.Page))
# Affichage du nombre de lignées traitées et du temps d'exécution
print(str(round(time.time() - startTime, 2)) + " secs")
print(str(len(gadf)) + " lines")
# Nettoyage du DataFrame
gadfCleanVersion = pd.DataFrame(gadf[list(map(is_clean_page, gadf['Page']))])
# Renommage des colonnes
gadfCleanVersion.rename(columns={'Page' : 'ga:pagePath', 'Theme' : 'ga:dimension31'}, inplace=True)
# Enregistrement du DataFrame sous forme de fichier CSV
gadfCleanVersion.to_csv(path_or_buf='page_and_theme.csv', index=False, encoding='utf-8')
# Affichage des 100 premières lignes du DataFrame
LapeyreCleanPages.head(100) |
# Fonction retournant une thématique en fonction du contenu de l'URL
def page_theme(url):
""" Assignation d'une thématique en fonction du contenu de l'URL """
theme = ""
if (re.search('^/
<h3>Importation du CSV et création de la nouvelle colonne « Thématique »</h3>
<pre lang="python" line="1"># On enregistre l'heure avant de démarrer le processing
startTime = time.time()
# On récupère le rapport non échantillonné
gadf = pd.read_csv('Pages.csv', encoding='utf-8')
# On garde uniquement la colonne "Pages" On peut également choisir la colonne à l'import
del gadf['Pages vues']
del gadf['Sorties']
# Création d'une colonne "Theme". Application de la fonction page_theme()
gadf['Theme'] = list(map(page_theme, gadf.Page))
# Affichage du nombre de lignées traitées et du temps d'exécution
print(str(round(time.time() - startTime, 2)) + " secs")
print(str(len(gadf)) + " lines")
# Nettoyage du DataFrame
gadfCleanVersion = pd.DataFrame(gadf[list(map(is_clean_page, gadf['Page']))])
# Renommage des colonnes
gadfCleanVersion.rename(columns={'Page' : 'ga:pagePath', 'Theme' : 'ga:dimension31'}, inplace=True)
# Enregistrement du DataFrame sous forme de fichier CSV
gadfCleanVersion.to_csv(path_or_buf='page_and_theme.csv', index=False, encoding='utf-8')
# Affichage des 100 premières lignes du DataFrame
LapeyreCleanPages.head(100)
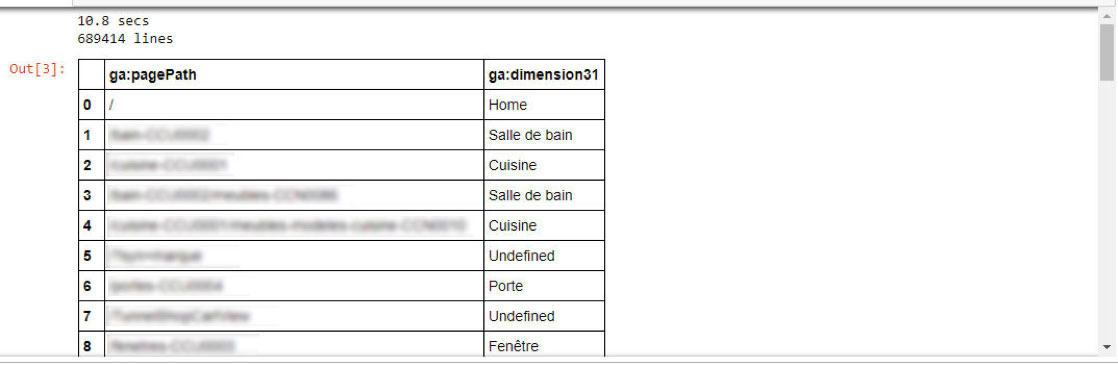
Et voilà ! A peine plus de 10 secondes de traitement pour enrichir près de 700 000 URL. Un jeu d’enfant 🙂
Note : si vous souhaitez gagner en temps d’exécution, le code est optimisable assez facilement :
- Ne pas utiliser de regex sur les tests de chaînes simples
- Compiler une bonne fois pour toute les regex qui vont être testées sur l’ensemble des lignes du DataFrame
J’ai réalisé ces optimisations et je suis tombé à 7 secondes d’exécution. A vous de juger ensuite du meilleur rapport temps d’écriture de code versus temps d’exécution, en fonction de la ré-utilisaton du dit-code et/ou du volume de données à traiter.
Ceci étant dit, revenons sur deux passages en particulier :
Le premier
1
2
| # Création d'une colonne "Theme". Application de la fonction page_theme()
gadf['Theme'] = list(map(page_theme, gadf.Page)) |
# Création d'une colonne "Theme". Application de la fonction page_theme()
gadf['Theme'] = list(map(page_theme, gadf.Page))
En une simple ligne de code…
- … On crée une nouvelle colonne sur notre DataFrame
- … On teste plus d’une dizaine d’expressions régulières sur environ 700 000 valeurs différentes
- … On applique une valeur au sein de la colonne sur les 700 000 lignes
Le second
1
2
| # Nettoyage du DataFrame
gadfCleanVersion = pd.DataFrame(gadf[list(map(is_clean_page, gadf['Page']))]) |
# Nettoyage du DataFrame
gadfCleanVersion = pd.DataFrame(gadf[list(map(is_clean_page, gadf['Page']))])
En une simple ligne de code, …
- … on applique une fonction qui retourne un booléen, en fonction de si l’URL est valide ou non.
- … on génère un itérateur dont on se sert pour créer une liste, qu’on applique en sélection sur notre premier DataFrame.
- … on récupère notre sélection au sein d’un nouveau DataFrame qui ne contient que les lignes considérées comme valides.
Le but final étant d’exclure les URL sur lesquelles on ne souhaite pas appliquer de thématique. Cela permet d’alléger le CSV qui servira à l’import.
C’est cette syntaxe extrêmement synthétique qui rend notamment Python pratique et puissant pour traiter de la donnée. Bien qu’on en ait ici qu’un bref aperçu, on peut aussi remercier la librairie Pandas et son objet « DataFrame » très pratique.
Maintenant que notre fichier CSV est prêt, il ne nous reste plus qu’à l’importer au sein de Google Analytics 360.
Etape #3 : Importation de la donnée enrichie au sein de Google Analytics 360
Google Analytics 360 propose deux types d’importation de données :
- Processing Time Import Mode
- Query Time Import Mode
Le premier mode d’importation est disponible également sur la version gratuite de GA. Il présente en revanche deux inconvénients rendant la fonctionnalité peu utile, voire même dangereuse à l’utilisation :
- Effet non rétro-actif sur la donnée : la donnée importée sera effective uniquement sur les hits récoltés après l’import de votre modèle. Impossible donc d’utiliser cette fonctionnalité dans un but d’analyse antérieure.
- Marquage irréversible : votre modèle sera gravé dans le marbre pour tous les hits générés à posteriori.
Attardons-nous plutôt sur le second mode.
Query Time Import Mode
Cette option n’est disponible que sur Google Analytics 360. Espérons qu’elle soit un jour étendue à Google Analytics standard. Le fonctionnement de ce mode est simple : à chaque fois que l’on requête de la donnée Google Analytics via une vue (Rapport natif, rapport personnalisé, requête Core API), Google réalise un processing à la volée pour intégrer la donnée importée.
Cela présente trois avantages non négligeables :
- Toute importation est rétro-active de facto, puisque le modèle est généré à la volée lors des requêtes, quelle que soit la date d’analyse.
- Vos importations n’ont aucune conséquence sur le schéma de données récoltées et stockées par Google.
- Il suffit de supprimer un modèle importé pour qu’il ne soit plus effectif.
L’import se réalise en deux étapes :
- Création d’un modèle d’import
- Import de la donnée sous forme de CSV respectant le modèle
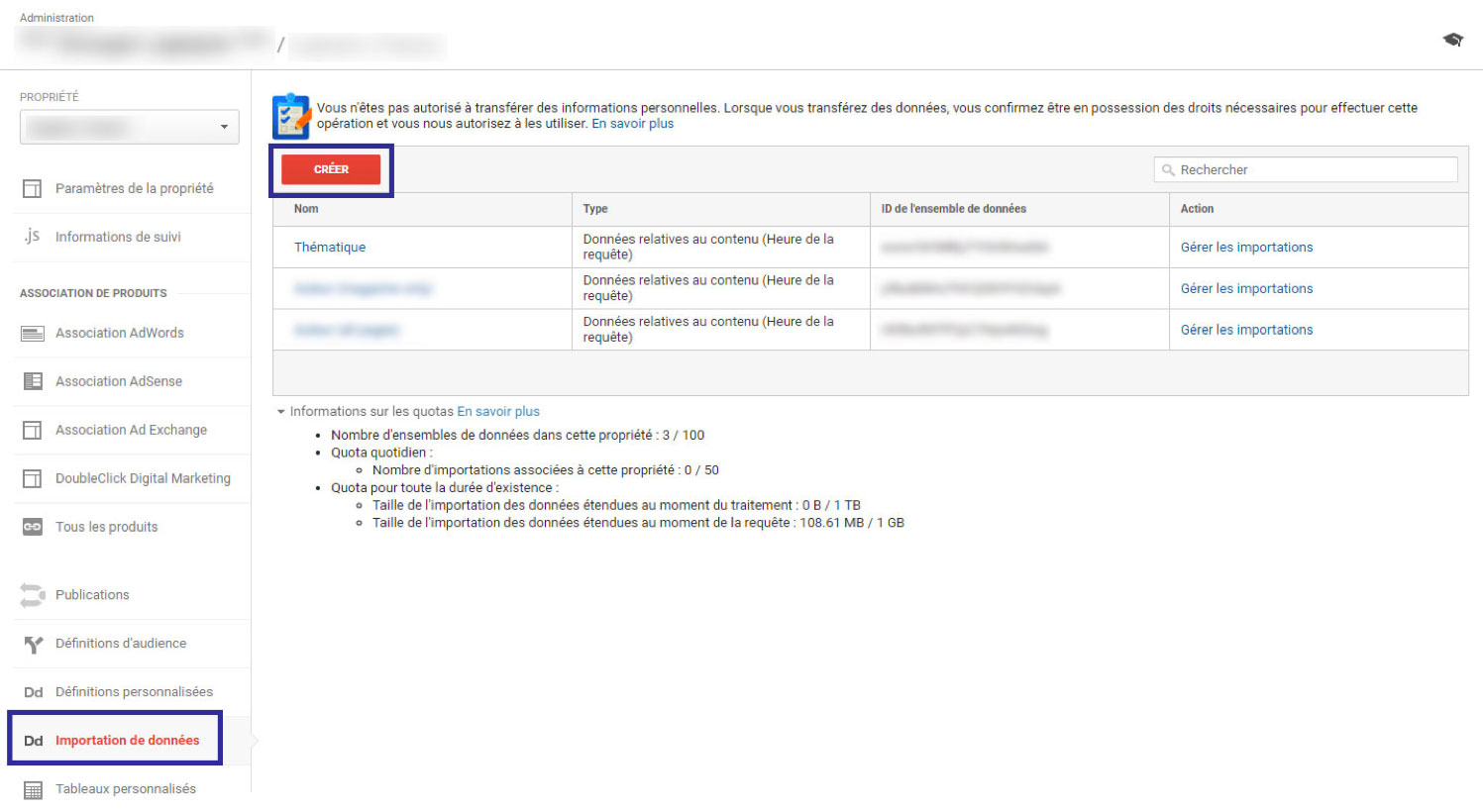
Création d’un modèle d’import
Rendez-vous dans : Admin => Importation de données => Créer
Choisissez ensuite l’option « Import de données relatives au contenu »
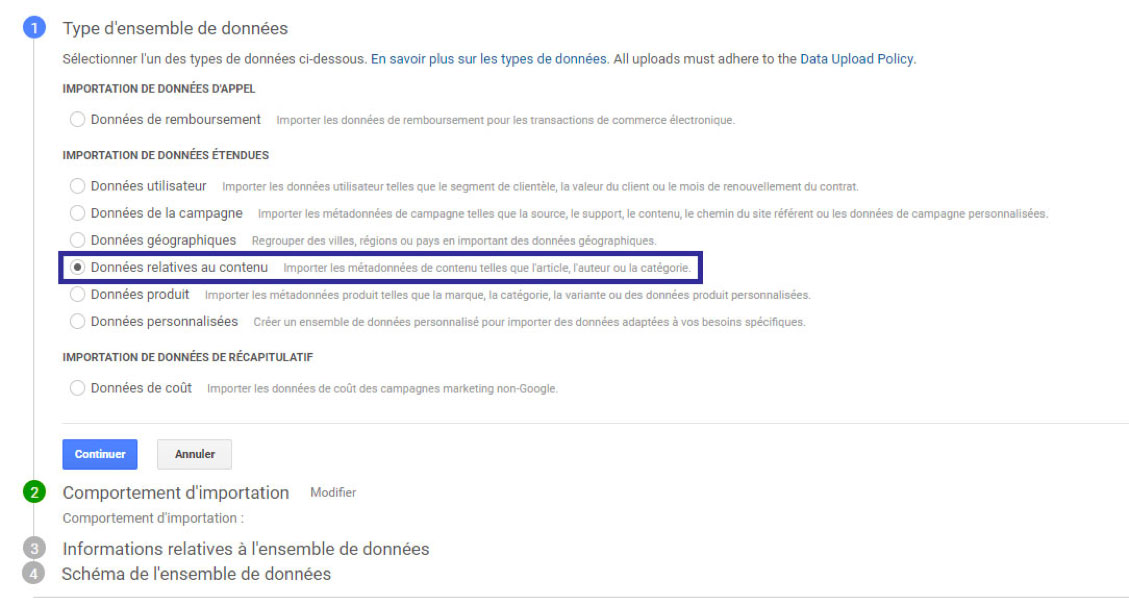
Puis on choisit le type d’import que l’on souhaite réaliser. On notera la traduction hasardeuse très élégante de « Time Query » par « Heure de la requête ».
Comme vous pouvez le constater, la fonctionnalité est encore en bêta. Jusqu’il y a peu, on rencontrait de sérieux soucis de bugs et d’instabilité lors de son utilisation. Mais depuis le 20 septembre tout semble être rentré dans l’ordre.
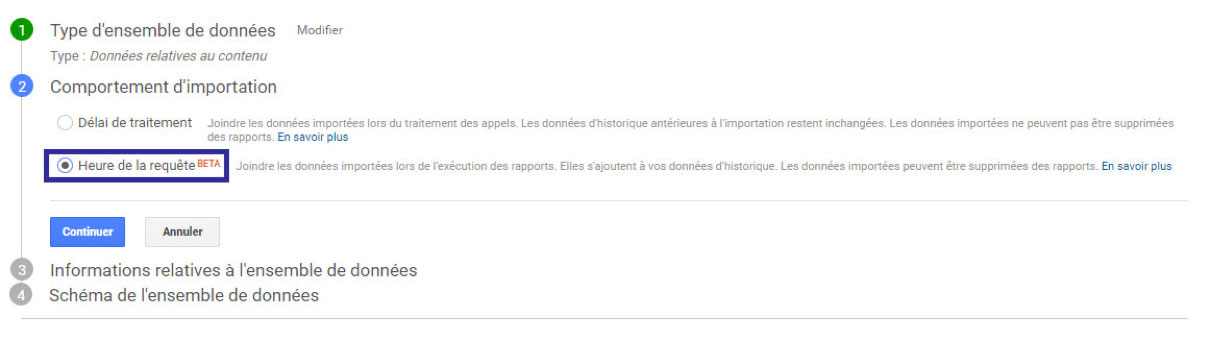
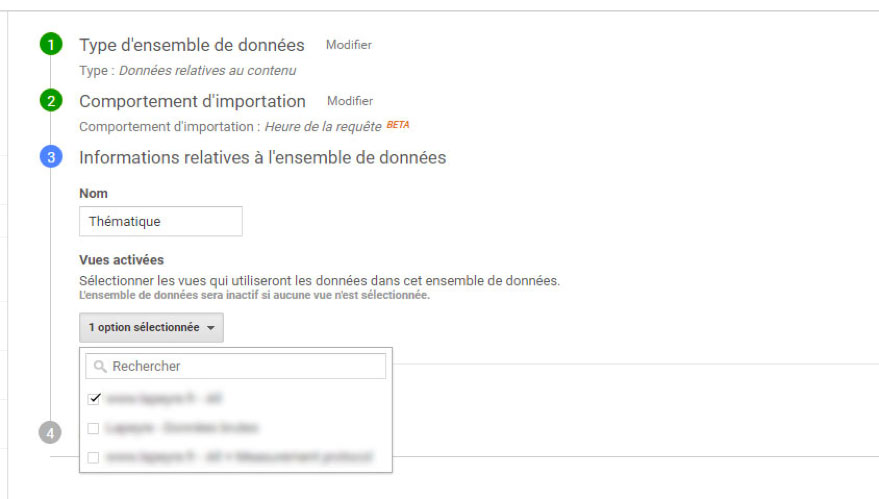
Nommer ensuite votre modèle d’importation et sélectionnez les vues auxquelles il sera rattaché :
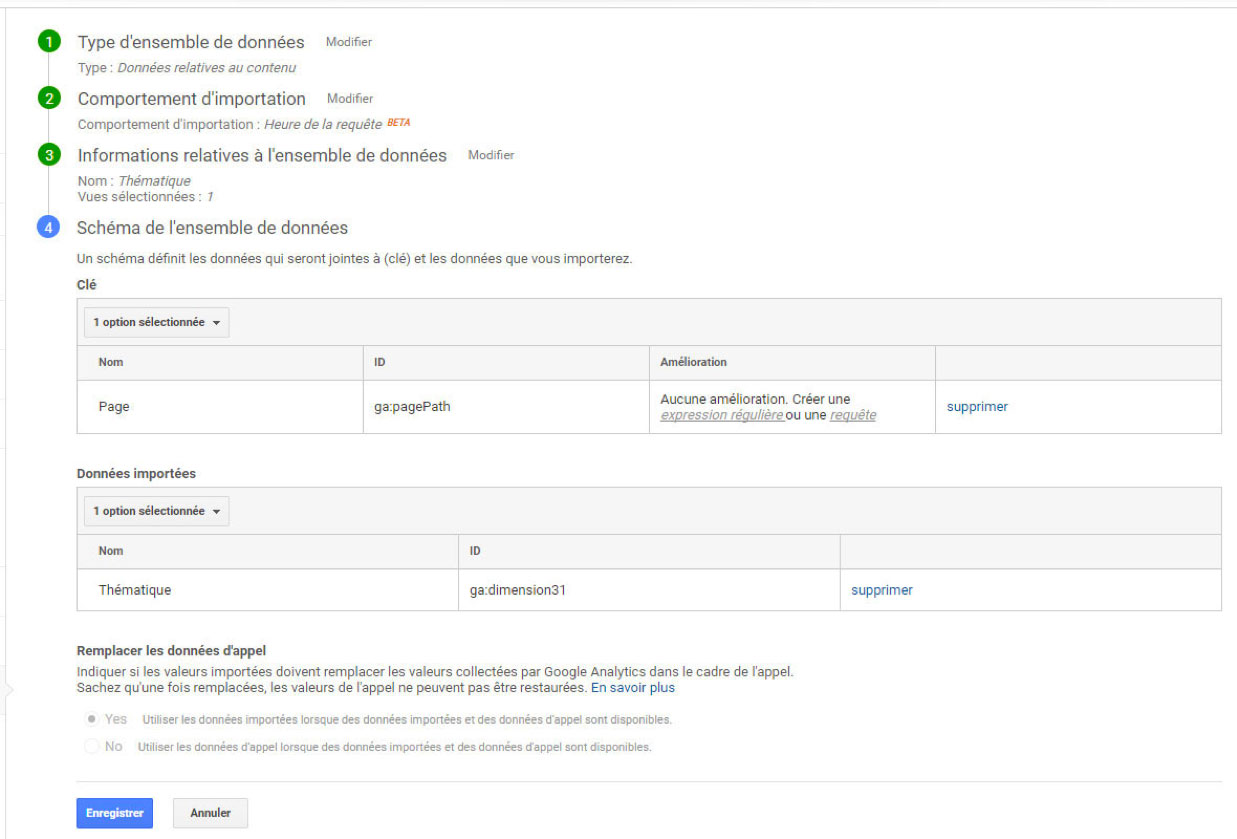
Enfin, il faut créer à proprement parler le modèle de données. Pour cela, on sélectionne la dimension qui servira de clef de jointure. Dans notre exemple, c’est la dimension « Page » qui endossera ce rôle. Ensuite, on sélectionne les dimensions que l’on souhaite enrichir. Il s’agit d’une custom dimension fraîchement créée, appelée « Thématique » et qui correspond à la Custom Dimension n°31 dans mon cas. On peut en sélectionner plusieurs si nécessaire.
On notera que sur la clef de jointure, il est possible de sélectionner qu’une partie des valeurs à prendre en compte lors de l’import, grâce à une expression régulière. C’est grossomodo le rôle de ma fonction de nettoyage expliquée plus haut, dans le script Python.
Note : si jamais des données importées et des données récoltées cohabitent, ce sont vos données importées qui prendront le dessus.
Maintenant que notre modèle est prêt, il ne nous reste plus qu’à importer le CSV.
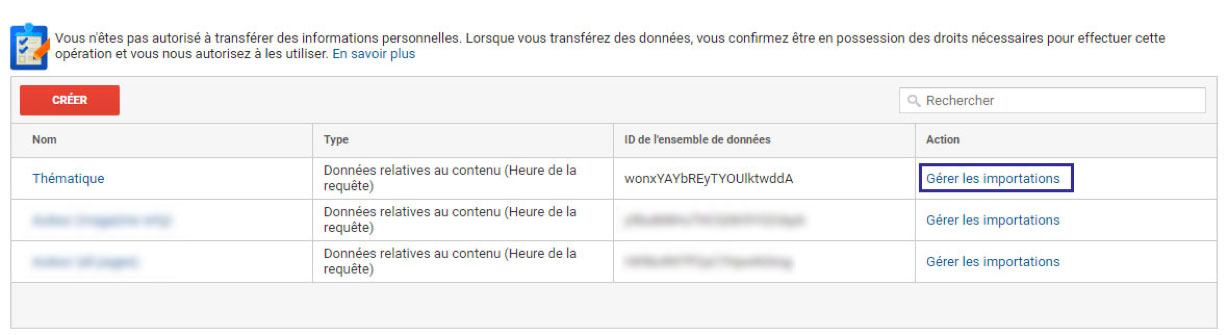

Et voilà ! Une fois l’importation terminée, il faudra compter une petite heure avant que le set de données soit utilisable au sein des requêtes API et des rapports.
Désormais, vous pouvez croiser votre dimension « Thématique » avec l’ensemble des dimensions et statistiques présentes dans le GA. Attention simplement à respecter la cohérence des scopes.
Les limites
La méthode détaillée dans cet article présente deux limites qui sont les suivantes.
Les valeurs récoltées dans le futur n’auront aucun impact sur l’enrichissement
Toutes les valeurs de la dimension « pagePath » qu’on a exportées ont permis d’enrichir la dimension « Thématique ». Et les analyses pourront être effectuées sur n’importe quelle période. En revanche, si après l’import, des pages vues génèrent de nouvelles URL – inconnues lors de l’export – alors celles-ci n’auront aucune thématique associée.
Ainsi il faudra réaliser régulièrement l’opération d’export / processing / import, afin de maintenir à jour les valeurs pour les futures URL. Il est possible d’automatiser une grande partie de l’opération, mais cela reste fastidieux.
C’est pour cette raison qu’il ne s’agit pas d’une méthode se substituant à l’enrichissement d’un plan de marquage. Ici, le but est plutôt de réaliser une analyse ou un enrichissement de manière ponctuelle, afin de répondre à une question à un instant T. La mise en œuvre de cette méthode doit donc être sous-tendue par un besoin spécifique, urgent ou ponctuel.
Le modèle de données GA au sein de Big Query n’est pas enrichi
Le mode d’importation « Time Query » présente de nombreux avantages de par le requêtage à la volée. En revanche, puisqu’on enrichit uniquement à l’affichage, le modèle de données n’est jamais affecté. Il faudra inéluctablement passer par Google Analytics pour retrouver cette donnée. Il sera donc impossible de retrouver les valeurs importées en Query Time au sein de Big Query.
Si vous souhaitez altérer et enrichir le modèle de données au sein de Big Query, il faudra alors passer par un import de type « Processing time ». L’inconvénient majeur est que ce mode n’affecte que les futurs hits récoltés. Et une fois la récolte commencée, il ne sera pas possible de faire machine arrière pour les hits enregistrés. Restez prudent, donc 🙂
Tous les modèles d’export ne sont pas réalisables en rapport non échantillonné
Il y a plusieurs cas où un rapport non échantillonné montrera ses limites :
- Exporter tous les hits sur une période donnée
- Exporter toutes les sessions sur une période donnée
- Croiser plusieurs dimensions au sein d’un même rapport
Pour les deux premiers exemples, vous aurez besoin de deux custom dimensions : une pour gérer l’identification unique de chaque hit et l’autre de chaque session. Mais au-delà de ça, ces modèles dépasseront rapidement la limite théorique des trois millions de lignes maximales par rapport.
Aller plus loin
Il faut bien retenir que :
- Grâce aux méthodes de « Dimension widening », le modèle de données Google Analytics n’est pas étanche à la donnée externe.
- Il est possible de réaliser des traitements de masse sur de la donnée Google Analytics sans nécessairement passer par Big Query.
En restant sur le même schéma, on pourrait imaginer par exemple exporter l’ensemble des User ID / Client ID avec les statistiques qui semblent pertinentes, puis réaliser un algorithme de scoring basé sur les données d’achat. Il suffirait ensuite de réimporter la donnée enrichie au sein d’une dimension dédiée dans Google Analytics. Ou bien encore, pourquoi ne pas imaginer une qualification basée uniquement sur le comportement de navigation et trouver des corrélations avec le comportement d’achat. Les seules limites seront votre imagination et la qualité du socle Analytics de vos actifs digitaux.
Pour conclure
J’ai tenté de décrire ici une méthode simple et efficace pour enrichir sa donnée GA. Il s’agit avant tout de présenter des moyens, à vous ensuite de les adapter pour arriver à vos fins. Certaines notions abordées sont à peine effleurées car infiniment vastes. Mais l’idée est de souligner que les solutions Analytics ne sont pas étanches aux données et aux traitements extérieurs. Et de rappeler qu’un web analyste dispose d’une panoplie de technologies et d’outils à sa disposition permettant de faire face à tout type de contrainte technique. Correctement utilisés, la mise en œuvre de vos analyses et enrichissements de données site-centric seront rendues possibles y compris sur des périmètres complexes et étendus.
Les commentaires sont ouverts pour les remarques et questions.
, url)):
theme = ‘Home’
elif (re.search(‘(fen(e|ê)tre|(baie(.*)vitr(é|e))’, url)):
theme = ‘Fenêtre’
elif (re.search(‘porte.*garage’, url)):
theme = ‘Porte de garage’
elif (re.search(‘(sol|mur|carrelage|parquet|lambri|parement)’, url)):
theme = ‘Sols et murs’
else:
theme = ‘Undefined’
return theme
Importation du CSV et création de la nouvelle colonne « Thématique »
Et voilà ! A peine plus de 10 secondes de traitement pour enrichir près de 700 000 URL. Un jeu d’enfant 🙂
Note : si vous souhaitez gagner en temps d’exécution, le code est optimisable assez facilement :
- Ne pas utiliser de regex sur les tests de chaînes simples
- Compiler une bonne fois pour toute les regex qui vont être testées sur l’ensemble des lignes du DataFrame
J’ai réalisé ces optimisations et je suis tombé à 7 secondes d’exécution. A vous de juger ensuite du meilleur rapport temps d’écriture de code versus temps d’exécution, en fonction de la ré-utilisaton du dit-code et/ou du volume de données à traiter.
Ceci étant dit, revenons sur deux passages en particulier :
Le premier
En une simple ligne de code…
- … On crée une nouvelle colonne sur notre DataFrame
- … On teste plus d’une dizaine d’expressions régulières sur environ 700 000 valeurs différentes
- … On applique une valeur au sein de la colonne sur les 700 000 lignes
Le second
En une simple ligne de code, …
- … on applique une fonction qui retourne un booléen, en fonction de si l’URL est valide ou non.
- … on génère un itérateur dont on se sert pour créer une liste, qu’on applique en sélection sur notre premier DataFrame.
- … on récupère notre sélection au sein d’un nouveau DataFrame qui ne contient que les lignes considérées comme valides.
Le but final étant d’exclure les URL sur lesquelles on ne souhaite pas appliquer de thématique. Cela permet d’alléger le CSV qui servira à l’import.
C’est cette syntaxe extrêmement synthétique qui rend notamment Python pratique et puissant pour traiter de la donnée. Bien qu’on en ait ici qu’un bref aperçu, on peut aussi remercier la librairie Pandas et son objet « DataFrame » très pratique.
Maintenant que notre fichier CSV est prêt, il ne nous reste plus qu’à l’importer au sein de Google Analytics 360.
Etape #3 : Importation de la donnée enrichie au sein de Google Analytics 360
Google Analytics 360 propose deux types d’importation de données :
- Processing Time Import Mode
- Query Time Import Mode
Le premier mode d’importation est disponible également sur la version gratuite de GA. Il présente en revanche deux inconvénients rendant la fonctionnalité peu utile, voire même dangereuse à l’utilisation :
- Effet non rétro-actif sur la donnée : la donnée importée sera effective uniquement sur les hits récoltés après l’import de votre modèle. Impossible donc d’utiliser cette fonctionnalité dans un but d’analyse antérieure.
- Marquage irréversible : votre modèle sera gravé dans le marbre pour tous les hits générés à posteriori.
Attardons-nous plutôt sur le second mode.
Query Time Import Mode
Cette option n’est disponible que sur Google Analytics 360. Espérons qu’elle soit un jour étendue à Google Analytics standard. Le fonctionnement de ce mode est simple : à chaque fois que l’on requête de la donnée Google Analytics via une vue (Rapport natif, rapport personnalisé, requête Core API), Google réalise un processing à la volée pour intégrer la donnée importée.
Cela présente trois avantages non négligeables :
- Toute importation est rétro-active de facto, puisque le modèle est généré à la volée lors des requêtes, quelle que soit la date d’analyse.
- Vos importations n’ont aucune conséquence sur le schéma de données récoltées et stockées par Google.
- Il suffit de supprimer un modèle importé pour qu’il ne soit plus effectif.
L’import se réalise en deux étapes :
- Création d’un modèle d’import
- Import de la donnée sous forme de CSV respectant le modèle
Création d’un modèle d’import
Rendez-vous dans : Admin => Importation de données => Créer
Choisissez ensuite l’option « Import de données relatives au contenu »
Puis on choisit le type d’import que l’on souhaite réaliser. On notera la traduction hasardeuse très élégante de « Time Query » par « Heure de la requête ».
Comme vous pouvez le constater, la fonctionnalité est encore en bêta. Jusqu’il y a peu, on rencontrait de sérieux soucis de bugs et d’instabilité lors de son utilisation. Mais depuis le 20 septembre tout semble être rentré dans l’ordre.
Nommer ensuite votre modèle d’importation et sélectionnez les vues auxquelles il sera rattaché :
Enfin, il faut créer à proprement parler le modèle de données. Pour cela, on sélectionne la dimension qui servira de clef de jointure. Dans notre exemple, c’est la dimension « Page » qui endossera ce rôle. Ensuite, on sélectionne les dimensions que l’on souhaite enrichir. Il s’agit d’une custom dimension fraîchement créée, appelée « Thématique » et qui correspond à la Custom Dimension n°31 dans mon cas. On peut en sélectionner plusieurs si nécessaire.
On notera que sur la clef de jointure, il est possible de sélectionner qu’une partie des valeurs à prendre en compte lors de l’import, grâce à une expression régulière. C’est grossomodo le rôle de ma fonction de nettoyage expliquée plus haut, dans le script Python.
Note : si jamais des données importées et des données récoltées cohabitent, ce sont vos données importées qui prendront le dessus.
Maintenant que notre modèle est prêt, il ne nous reste plus qu’à importer le CSV.
Et voilà ! Une fois l’importation terminée, il faudra compter une petite heure avant que le set de données soit utilisable au sein des requêtes API et des rapports.
Désormais, vous pouvez croiser votre dimension « Thématique » avec l’ensemble des dimensions et statistiques présentes dans le GA. Attention simplement à respecter la cohérence des scopes.
Les limites
La méthode détaillée dans cet article présente deux limites qui sont les suivantes.
Les valeurs récoltées dans le futur n’auront aucun impact sur l’enrichissement
Toutes les valeurs de la dimension « pagePath » qu’on a exportées ont permis d’enrichir la dimension « Thématique ». Et les analyses pourront être effectuées sur n’importe quelle période. En revanche, si après l’import, des pages vues génèrent de nouvelles URL – inconnues lors de l’export – alors celles-ci n’auront aucune thématique associée.
Ainsi il faudra réaliser régulièrement l’opération d’export / processing / import, afin de maintenir à jour les valeurs pour les futures URL. Il est possible d’automatiser une grande partie de l’opération, mais cela reste fastidieux.
C’est pour cette raison qu’il ne s’agit pas d’une méthode se substituant à l’enrichissement d’un plan de marquage. Ici, le but est plutôt de réaliser une analyse ou un enrichissement de manière ponctuelle, afin de répondre à une question à un instant T. La mise en œuvre de cette méthode doit donc être sous-tendue par un besoin spécifique, urgent ou ponctuel.
Le modèle de données GA au sein de Big Query n’est pas enrichi
Le mode d’importation « Time Query » présente de nombreux avantages de par le requêtage à la volée. En revanche, puisqu’on enrichit uniquement à l’affichage, le modèle de données n’est jamais affecté. Il faudra inéluctablement passer par Google Analytics pour retrouver cette donnée. Il sera donc impossible de retrouver les valeurs importées en Query Time au sein de Big Query.
Si vous souhaitez altérer et enrichir le modèle de données au sein de Big Query, il faudra alors passer par un import de type « Processing time ». L’inconvénient majeur est que ce mode n’affecte que les futurs hits récoltés. Et une fois la récolte commencée, il ne sera pas possible de faire machine arrière pour les hits enregistrés. Restez prudent, donc 🙂
Tous les modèles d’export ne sont pas réalisables en rapport non échantillonné
Il y a plusieurs cas où un rapport non échantillonné montrera ses limites :
- Exporter tous les hits sur une période donnée
- Exporter toutes les sessions sur une période donnée
- Croiser plusieurs dimensions au sein d’un même rapport
Pour les deux premiers exemples, vous aurez besoin de deux custom dimensions : une pour gérer l’identification unique de chaque hit et l’autre de chaque session. Mais au-delà de ça, ces modèles dépasseront rapidement la limite théorique des trois millions de lignes maximales par rapport.
Aller plus loin
Il faut bien retenir que :
- Grâce aux méthodes de « Dimension widening », le modèle de données Google Analytics n’est pas étanche à la donnée externe.
- Il est possible de réaliser des traitements de masse sur de la donnée Google Analytics sans nécessairement passer par Big Query.
En restant sur le même schéma, on pourrait imaginer par exemple exporter l’ensemble des User ID / Client ID avec les statistiques qui semblent pertinentes, puis réaliser un algorithme de scoring basé sur les données d’achat. Il suffirait ensuite de réimporter la donnée enrichie au sein d’une dimension dédiée dans Google Analytics. Ou bien encore, pourquoi ne pas imaginer une qualification basée uniquement sur le comportement de navigation et trouver des corrélations avec le comportement d’achat. Les seules limites seront votre imagination et la qualité du socle Analytics de vos actifs digitaux.
Pour conclure
J’ai tenté de décrire ici une méthode simple et efficace pour enrichir sa donnée GA. Il s’agit avant tout de présenter des moyens, à vous ensuite de les adapter pour arriver à vos fins. Certaines notions abordées sont à peine effleurées car infiniment vastes. Mais l’idée est de souligner que les solutions Analytics ne sont pas étanches aux données et aux traitements extérieurs. Et de rappeler qu’un web analyste dispose d’une panoplie de technologies et d’outils à sa disposition permettant de faire face à tout type de contrainte technique. Correctement utilisés, la mise en œuvre de vos analyses et enrichissements de données site-centric seront rendues possibles y compris sur des périmètres complexes et étendus.
Les commentaires sont ouverts pour les remarques et questions.